一、Debezium简介
Debezium是一个开源项目,为捕获数据更改(change data capture,CDC)提供了一个低延迟的流式处理平台。你可以安装并且配置Debezium去监控你的数据库,然后你的应用就可以消费对数据库的每一个行级别(row-level)的更改。只有已提交的更改才是可见的,所以你的应用不用担心事务(transaction)或者更改被回滚(roll back)。Debezium为所有的数据库更改事件提供了一个统一的模型,所以你的应用不用担心每一种数据库管理系统的错综复杂性。另外,由于Debezium用持久化的、有副本备份的日志来记录数据库数据变化的历史,因此,你的应用可以随时停止再重启,而不会错过它停止运行时发生的事件,保证了所有的事件都能被正确地、完全地处理掉。
监控数据库,并且在数据变动的时候获得通知一直是很复杂的事情。关系型数据库的触发器可以做到,但是只对特定的数据库有效,而且通常只能更新数据库内的状态(无法和外部的进程通信)。一些数据库提供了监控数据变动的API或者框架,但是没有一个标准,每种数据库的实现方式都是不同的,并且需要大量特定的知识和理解特定的代码才能运用。确保以相同的顺序查看和处理所有更改,同时最小化影响数据库仍然非常具有挑战性。
Debezium提供了模块为你做这些复杂的工作。一些模块是通用的,并且能够适用多种数据库管理系统,但在功能和性能方面仍有一些限制。另一些模块是为特定的数据库管理系统定制的,所以他们通常可以更多地利用数据库系统本身的特性来提供更多功能。
Github:https://github.com/debezium/debezium
官网:https://debezium.io/
二、安装
1. 使用docker compose安装
version: '2'
services:
zookeeper:
image: quay.io/debezium/zookeeper:2.5
ports:
- 2181:2181
- 2888:2888
- 3888:3888
kafka:
image: quay.io/debezium/kafka:2.5
ports:
- 9092:9092
links:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
connect:
image: quay.io/debezium/connect:2.5
ports:
- 8083:8083
- 5005:5005
links:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_source_connect_statuses
kafka-ui:
image: provectuslabs/kafka-ui:latest
ports:
- "9093:8080"
environment:
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092
links:
- kafka
debezium-ui:
image: debezium/debezium-ui:2.5
ports:
- "8080:8080"
environment:
- KAFKA_CONNECT_URIS=http://connect:8083
links:
- connect
2. 浏览器访问
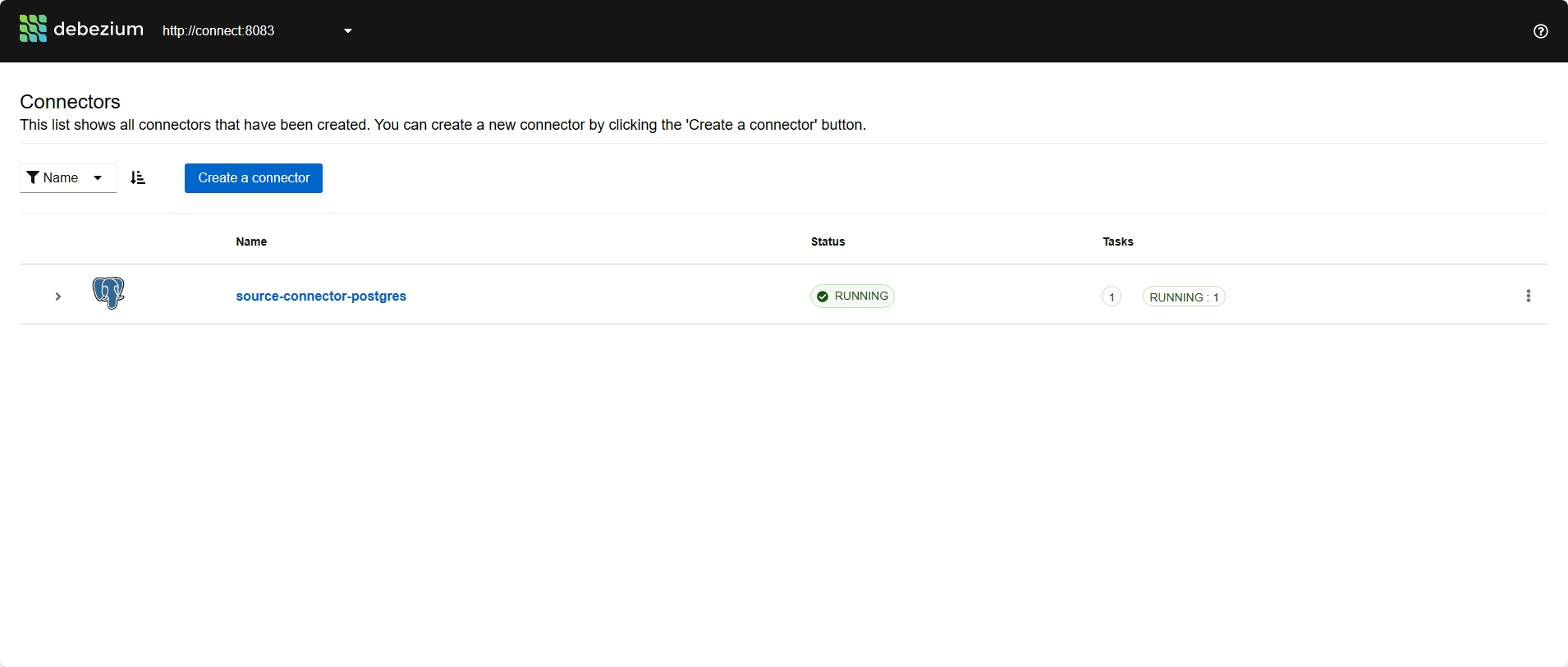
Debezium UI:http://xxx.xxx.xxx.xxx:8080/
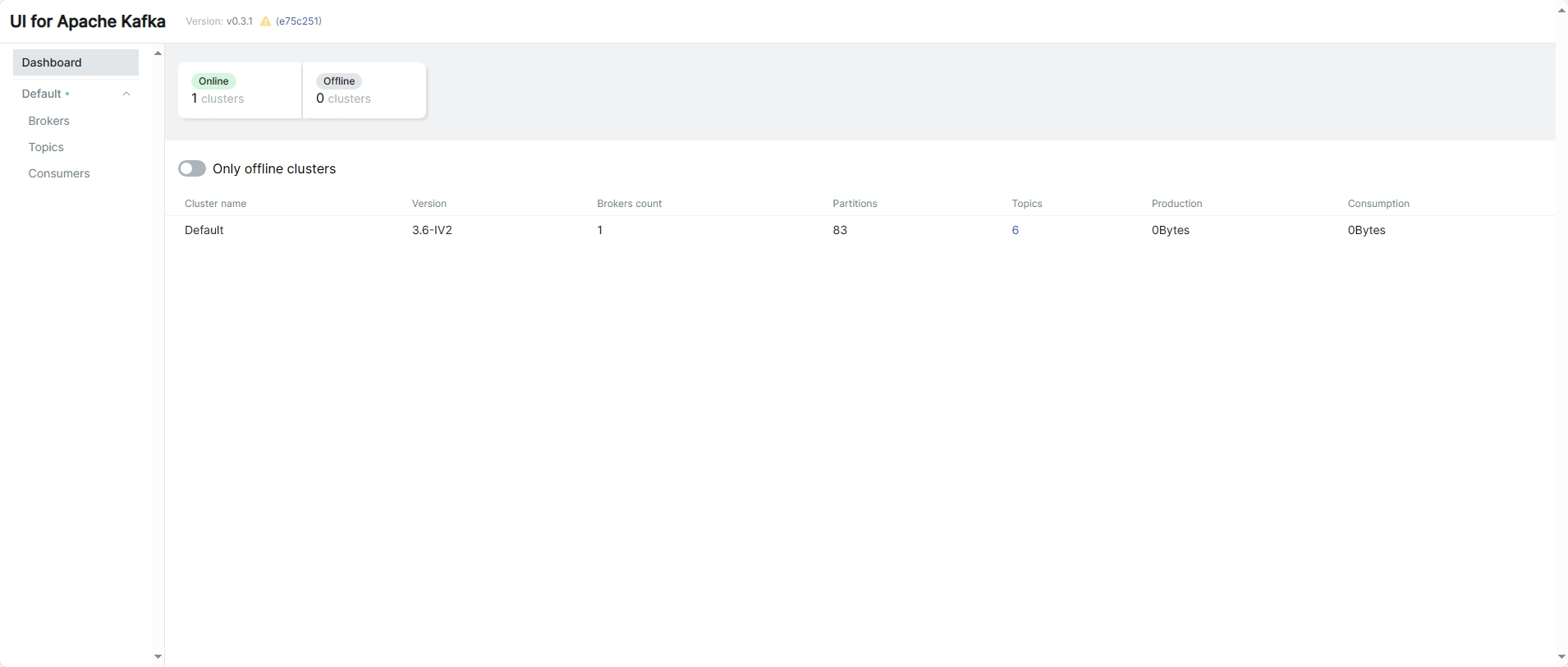
UI for Apache Kafka:http://xxx.xxx.xxx.xxx:9093/ui
三、Postgres数据库使用示例
说明
- PG数据库获取数据变更,要设置日志并安装解码插件
- PG数据库获取数据变更,是使用的基于wal日志的逻辑复制槽,通过使用插件可将日志解码。
# 查询复制槽slot信息 select * from pg_replication_slots - Postgres connector支持三个用于从数据库服务器捕获流式数据更改的逻辑解码插件:decoderbufs(默认)、wal2json以及pgoutput。
数据流向图示

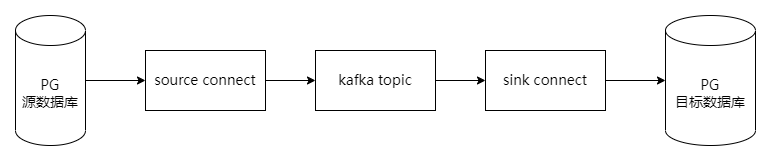
1. connect容器中加入依赖jar
- kafka-connect-jdbc-5.3.2.jar:将kafka中的数据通过jdbc写入目标数据库
- postgresql-42.6.0.jar:postgresql连接驱动
执行命令
docker exec -it connect容器ID /bin/mkdir /kafka/connect/kafka-connect-jdbc
docker cp kafka-connect-jdbc-5.3.2.jar connect容器ID:/kafka/connect/kafka-connect-jdbc
docker cp postgresql-42.6.0.jar connect容器ID:/kafka/connect/kafka-connect-jdbc
docker restart connect容器ID
2. 创建source connect
可以通过Debezium UI创建,使用postman直接调用connect api更方便
# 创建source连接器
POST http://[connect ip]:8083/connectors/
{
"name": "source-connector-postgres",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "数据库地址",
"database.port": "5432",
"database.user": "用户名",
"database.password": "用户密码",
"database.dbname" : "数据库名",
"topic.prefix": "Kafka Topic前缀",
"table.include.list": "public.表名"
}
}
使用curl发送请求
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://[connect ip]:8083/connectors/ -d \
'{
"name": "source-connector-postgres",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "数据库地址",
"database.port": "5432",
"database.user": "用户名",
"database.password": "用户密码",
"database.dbname" : "数据库名",
"topic.prefix": "Kafka Topic前缀",
"table.include.list": "public.表名"
}
}'
# 查看连接器列表
GET http://[connect ip]:8083/connectors/
# 查看连接器状态
GET http://[connect ip]:8083/connectors/[connect名称]/status
- 创建后,查看连接器状态,均成功后,稍等片刻,可通过UI for Apache Kafka看到创建的topic
- Debezium 的 PostgreSQL 连接器在第一次启动时,默认会执行数据库的初始一致性快照,导出全量数据再导入到Kafka。
3. 创建sink连接器
sink连接器将topic中的数据通过kafka-connect-jdbc写入目标数据库
# 创建sink连接器
POST http://[connect ip]:8083/connectors/
{
"name": "sink-connector-postgres",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "source创建的topic",
"connection.url": "jdbc:postgresql://数据库连接地址:5432/数据库名?user=账户名&password=账户密码",
"table.name.format": "public.目标表表名",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"auto.create": "false",
"auto.evolve": "false",
"insert.mode": "upsert",
"delete.enabled": "true",
"pk.fields": "id",
"pk.mode": "record_key"
}
}
# 查看连接器状态
GET http://[connect ip]:8083/connectors/[connect名称]/status
# 删除连接器
DELETE http://[connect ip]:8083/connectors/[connect名称]
创建成功后,稍等片刻,可以看到目标表中同步过来的数据
参考文章
- Debezium PostgreSQL Connector 的快照模式 snapshot.mode:https://www.modb.pro/db/397480
- 一文教你基于Debezium与Kafka构建数据同步迁移:https://www.bilibili.com/read/cv22017570/
- JDBC connector进行表数据增量同步过程中的源表与目标表时间不一致问题解决:https://blog.51cto.com/liujinhui/5668871