一、说明
Flink
Flink支持两种计算模式:批处理和流处理,流处理又分为:有界流和无界流。
批处理是指将一批数据集合在一起,一次性输入到计算系统中进行处理的方式。批处理通常是离线处理,即不需要实时响应用户请求,而是按照一定的时间间隔、容量大小或者规则定期进行批量处理。
流处理是指对实时数据流进行连续的、实时的处理方式。与批处理不同,流处理通常需要以毫秒或者微秒级别响应事件的发生,并及时产生相应的反馈和输出。
DataSet API用于批处理,DataStream API用于流式处理。
本示例说明
WordCount是大数据处理系统的“Hello World”。它计算文本集合中单词的频率。该算法分两步进行:首先,文本将文本分成单个单词。其次,对单词进行分组和计
数。
本实例实现无界流处理WordCount。
二、创建MAVEN工程
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink-job</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.12.7</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-access</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>
</project>
logback.xml
<configuration>
<property name="CONSOLE_LOG_PATTERN"
value="%yellow(%d{yyyy-MM-dd HH:mm:ss.SSS}) [%blue(%thread)] %highlight(%-5level) %green(%logger{60}) %blue(%file:%line) %X{sourceThread} - %cyan(%msg%n)"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
</root>
<logger name="akka" level="INFO">
<appender-ref ref="console"/>
</logger>
<logger name="org.apache.kafka" level="INFO">
<appender-ref ref="console"/>
</logger>
<logger name="org.apache.hadoop" level="INFO">
<appender-ref ref="console"/>
</logger>
<logger name="org.apache.zookeeper" level="INFO">
<appender-ref ref="console"/>
</logger>
<logger name="org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline" level="ERROR">
<appender-ref ref="console"/>
</logger>
</configuration>
WordCountUnboundedDemo.java
package job.demo;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* dataStream 实现wordCount 读socket(无界流)
*/
public class WordCountUnboundedDemo {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据:从文件中读取
// 在主机上安装netcat,然后启动服务,输入各种单词
// yum install -y netcat
// nc -lk 7777
DataStreamSource<String> socketDS = env.socketTextStream("192.168.100.101", 7777);
// 3. 处理数据:切分、转换、分组、聚合
socketDS
.flatMap(
(String s, Collector<Tuple2<String, Integer>> collector) -> {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1));
}
}
)
// 这里由于Lambda表达式存在类型擦除,所以必须指定返回元素的类型
.returns(Types.TUPLE(Types.STRING,Types.INT))
.keyBy(stringIntegerTuple2 -> stringIntegerTuple2.f0)
.sum(1)
.print();
// 4. 输出
// 5、执行
env.execute();
}
}
三、本地运行
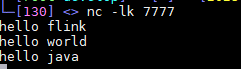
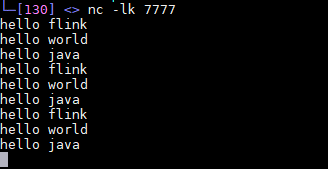
服务端运行nc模拟数据源
yum install -y netcat
nc -lk 7777
idea中运行
-
flink的依赖服务器打包部署是需要排除的,maven依赖中设置了
<scope>provided</scope>, 本地依赖,需要做如下设置
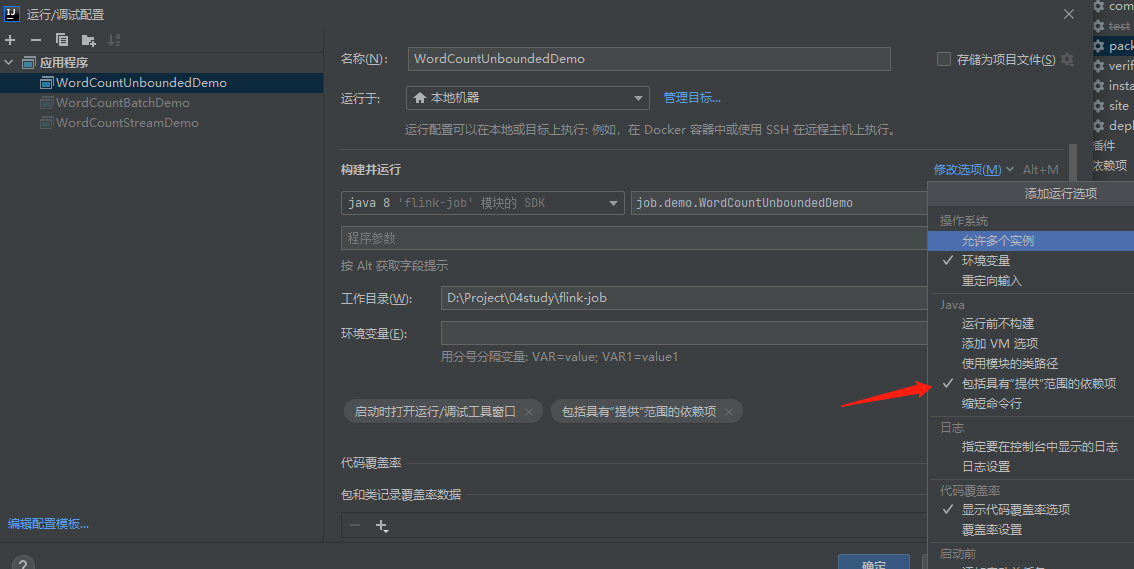
-
运行类
-
nc模拟数据源
-
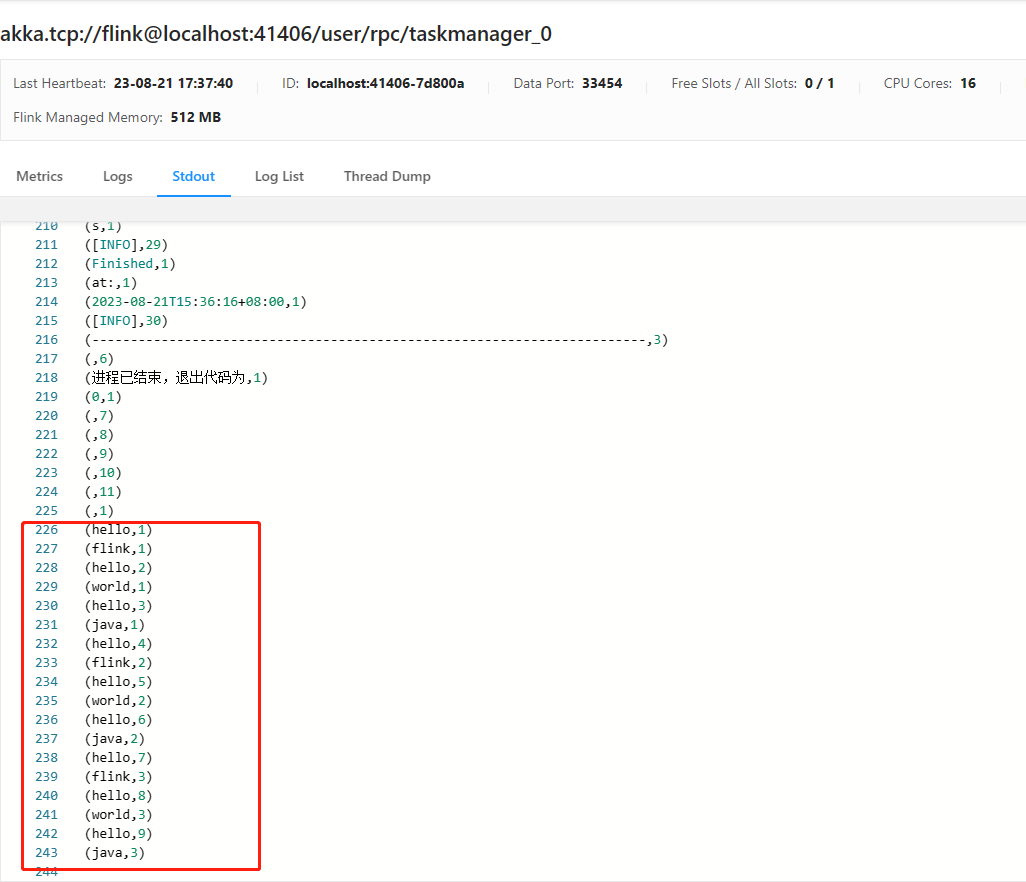
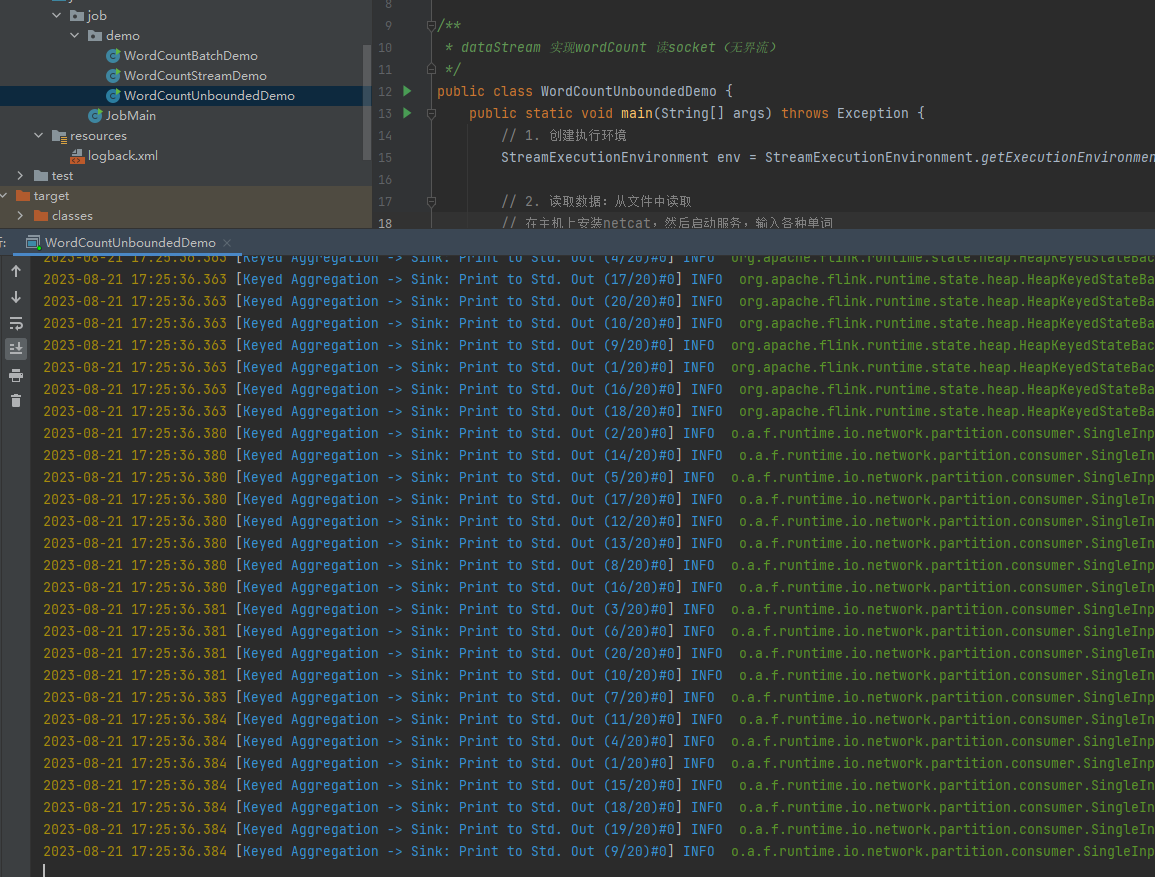
idea的控制台中,就会出现分词统计结果
16> (flink,1)
6> (hello,1)
11> (world,1)
6> (hello,2)
4> (java,1)
6> (hello,3)
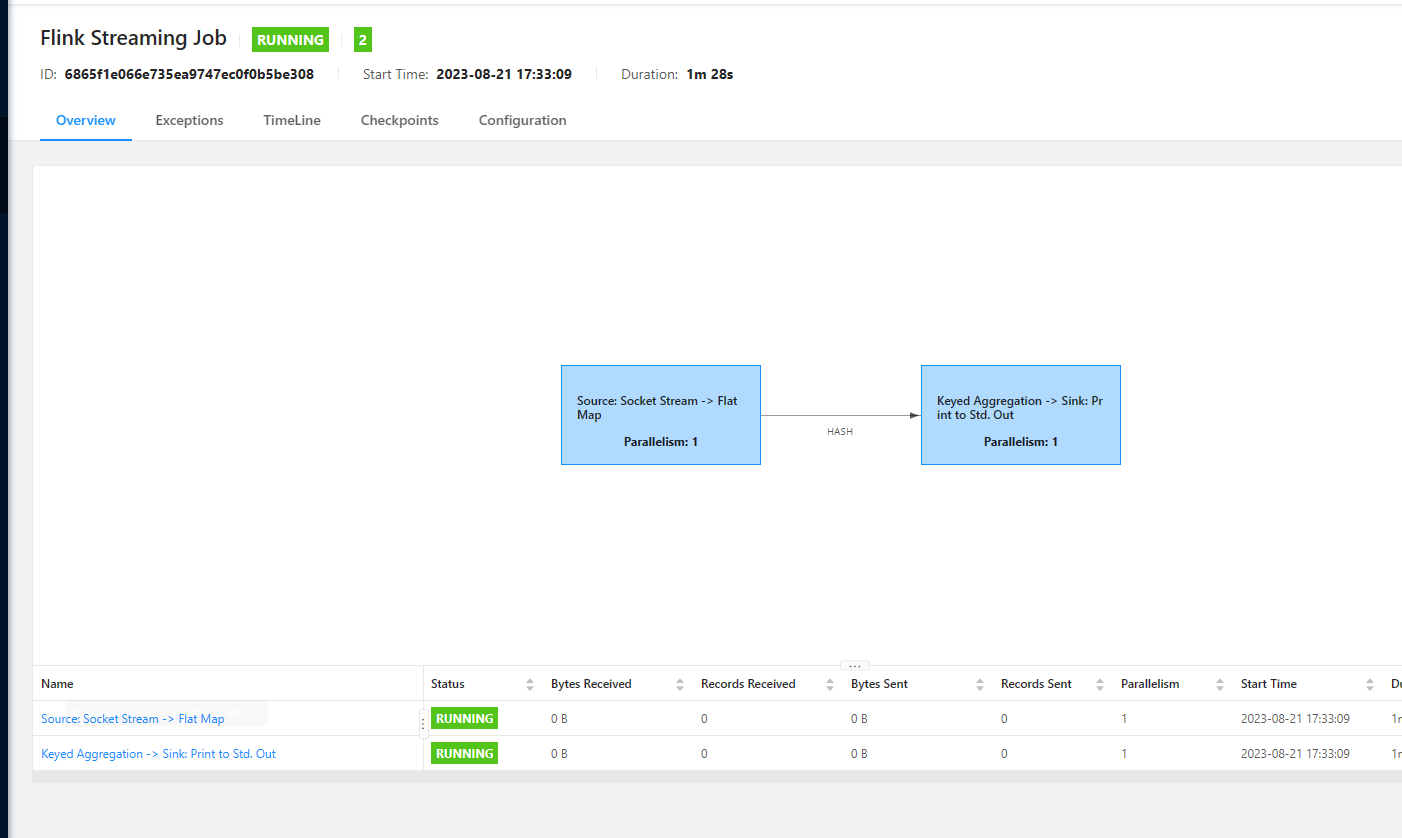
四、服务器运行
-
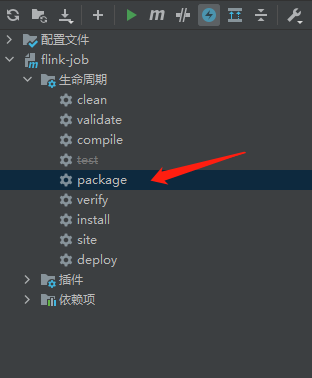
打包maven工程
-
上传jar包到flink

-
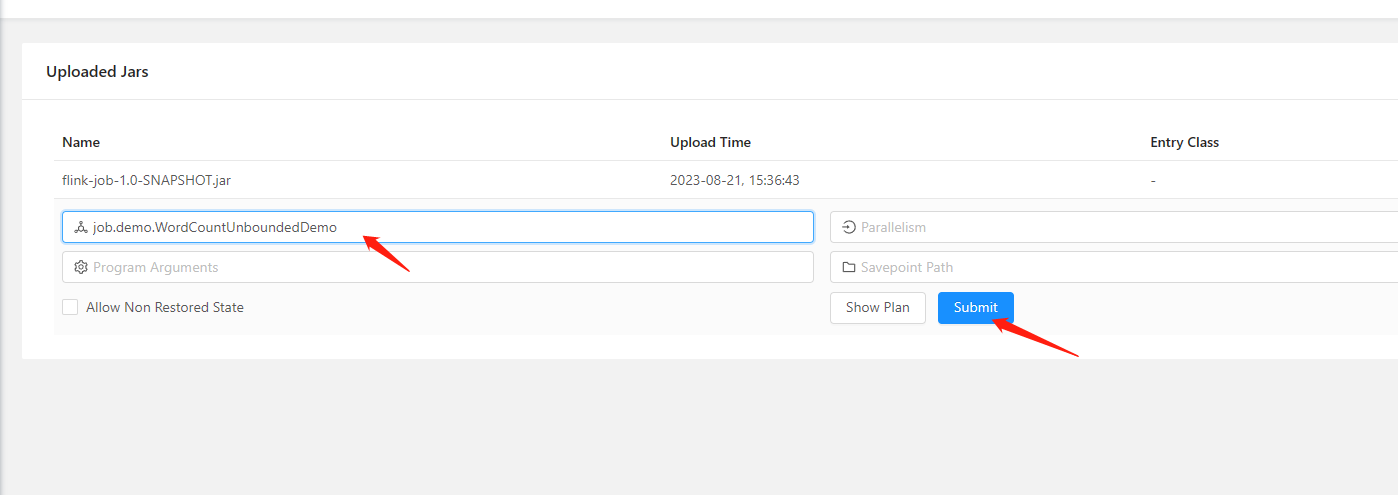
运行jar包中的任务类
注意先关闭本地idea中运行的类
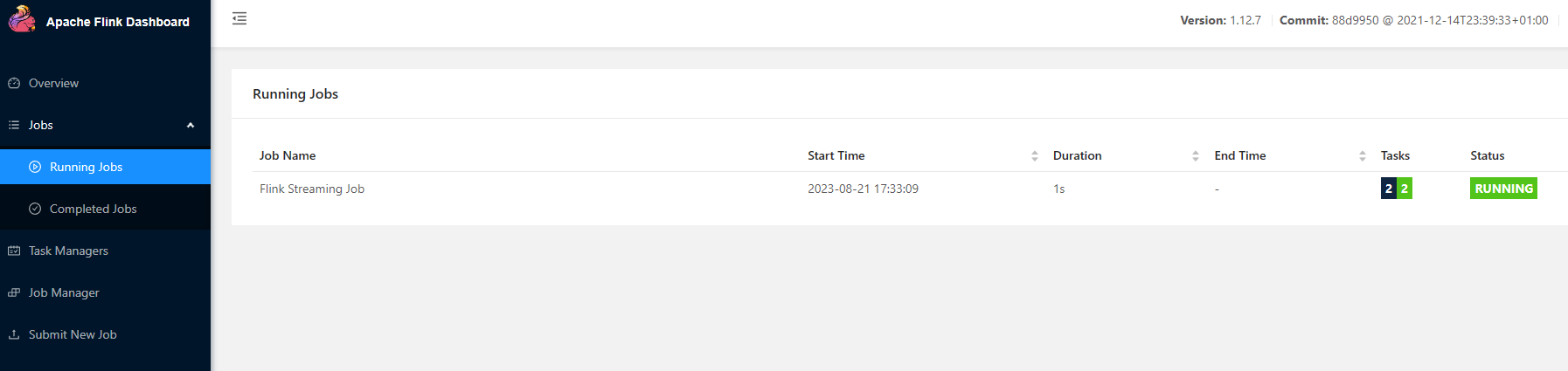
-
nc模拟数据源
-
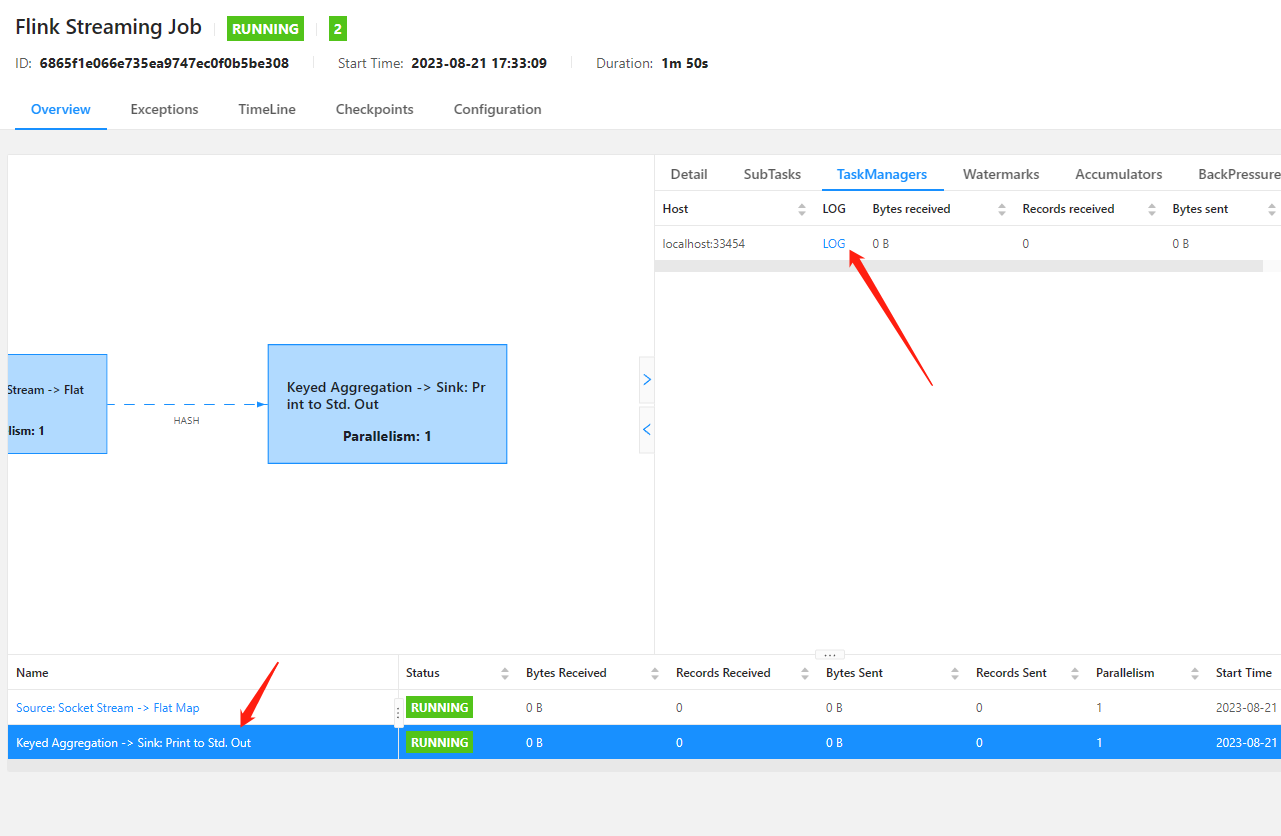
flink中查看运行日志